

mqtt选择



|
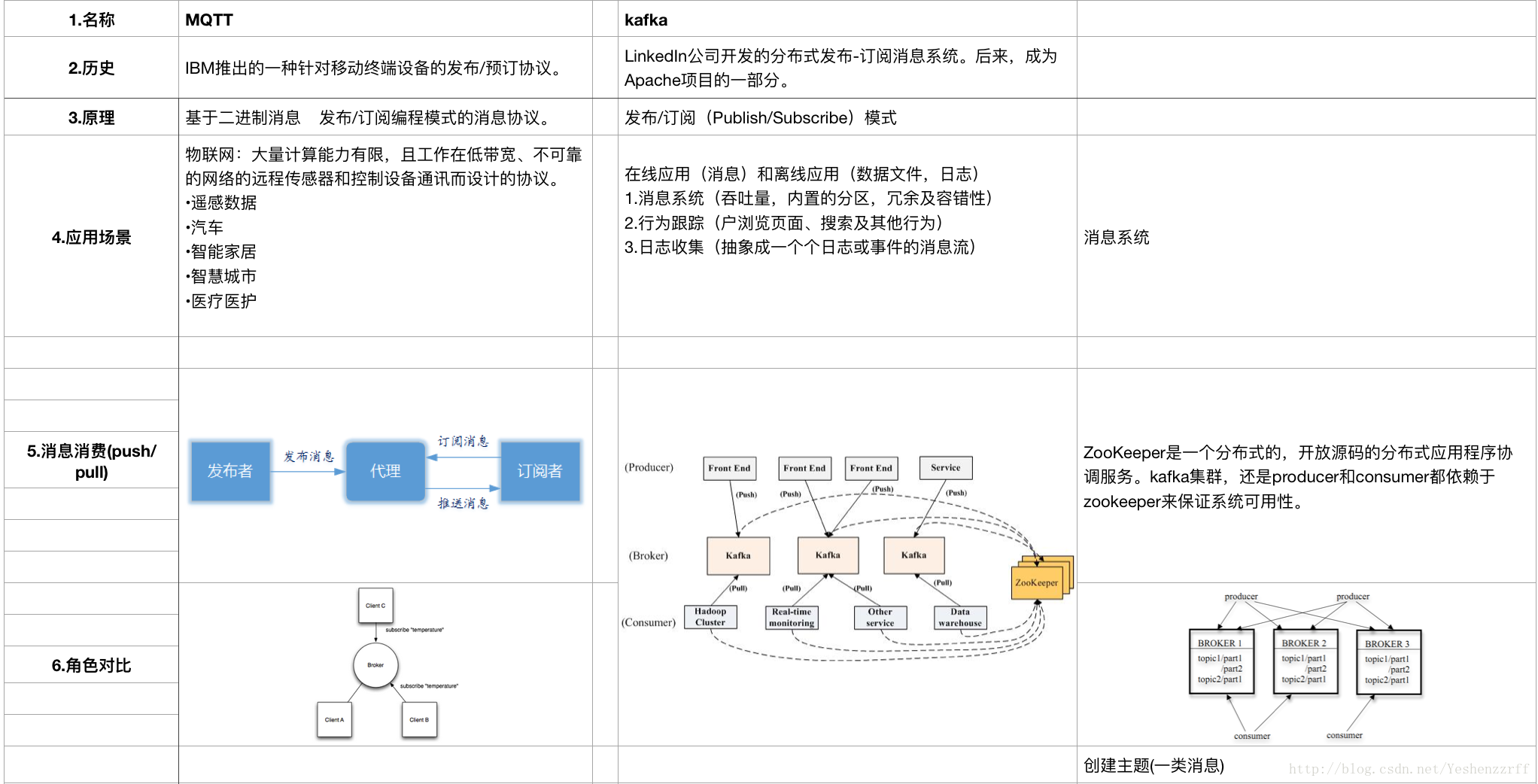
1.名称 |
MQTT |
|
kafka |
|
|
2.历史 |
IBM 推出的一种针对移动终端设备的发布 / 预订协议。 |
|
LinkedIn 公司开发的分布式发布 - 订阅消息系统。后来,成为 Apache 项目的一部分。 |
|
|
3.原理 |
基于二进制消息 发布 / 订阅编程模式的消息协议。 |
|
发布 / 订阅(Publish/Subscribe)模式 |
|
|
4.应用场景 |
物联网:大量计算能力有限,且工作在低带宽、不可靠的网络的远程传感器和控制设备通讯而设计的协议。 •遥感数据 •汽车 •智能家居 •智慧城市 •医疗医护
|
|
在线应用(消息)和离线应用(数据文件,日志) 1. 消息系统(吞吐量,内置的分区,冗余及容错性) 2. 行为跟踪(户浏览页面、搜索及其他行为) 3. 日志收集(抽象成一个个日志或事件的消息流)
|
消息系统 |
|
|
|
|
|
|
|
|
|
|
|
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务。kafka 集群,还是 producer 和 consumer 都依赖于 zookeeper 来保证系统可用性。 |
|
|
||||
|
5.消息消费(push/pull) |
||||
|
|
||||
|
|
||||
|
|
||||
|
|
|
|
|
|
|
|
||||
|
6.角色对比 |
||||
|
|
||||
|
|
||||
|
|
|
|
|
创建主题 (一类消息) |
|
5.主题(Topic) |
主题筛选器:通过主题对消息进行分类的 层级主题:通过反斜杠表示多个层级关系; 通过通配符进行过滤:+ 可以过滤一个层级,而 * 只能出现在主题最后表示过滤任意级别的层级。举个例子: • building-b/floor-5:代表 B 楼 5 层的设备。 • +/floor-5:代表任何一个楼的 5 层的设备。 • building-b/*:代表 B 楼所有的设备。 注意,MQTT 允许使用通配符订阅主题,但是并不允许使用通配符广播。 |
|
每个 topic 划分为多个 partition。 每个 partition 在存储层面是 append log 文件。 |
|
|
6.服务质量(Quality of Service,QoS) |
为了满足不同的场景,MQTT 支持三种不同级别的服务质量为不同场景提供消息可靠性: •级别 0:尽力而为。消息可能会丢,但绝不会重复传输 •级别 1:消息绝不会丢,但可能会重复传输 •级别 2:恰好一次。每条消息肯定会被传输一次且仅传输一次 |
|
级别 1,Kafka 利用这一特点减少确认从而大大提高了并发。 |
|
|
7.存储方式 |
内存、redis、mongdb 等 |
|
磁盘 |
将消息持久化到磁盘,因此可用于批量消费。因为 kafka 是对日志文件进行 append 操作, 因此磁盘检索的开支是较小的; 为了减少磁盘写入的次数,broker 会将消息暂时 buffer 起来, 当消息的个数 (或尺寸) 达到一定阀值时, 再 flush 到磁盘, 这样减少了磁盘 IO 调用的次数. |
|
8.设计原则(为什么MQTT用来做物联网消息传输、Kafka用来做日志收集) |
1. 协议精简,不添加可有可无的功能。 2. 发布 / 订阅(Pub/Sub)模式,方便消息在传感器之间传递。 3. 允许用户动态创建主题,零运维成本。 4. 把传输量降到最低以提高传输效率。(固定长度的头部是 2 字节),协议交换最小化,以降低网络流量。
5. 把低带宽、高延迟、不稳定的网络等因素考虑在内。 6. 支持连续的会话控制。 7. 理解客户端计算能力可能很低。 8. 提供服务质量管理。 9. 假设数据不可知,不强求传输数据的类型与格式,保持灵活性。
|
|
吞吐量 1. 数据磁盘持久化:消息不在内存中 cache,直接写入到磁盘,充分利用磁盘的顺序读写性能 2.zero-copy:减少 IO 操作步骤 3. 数据批量发送 4. 数据压缩 5.Topic 划分为多个 partition,提高 parallelism 负载均衡 1. 生产者发送消息到 pattition 2. 存在多个 partiiton,每个 partition 有自己的 replica,每个 replica 分布在不同的 Broker 节点上 3. 多个 partition 需要选取出 lead partition,lead partition 负责读写,并由 zookeeper 负责 fail over 4. 通过 zookeeper 管理 broker 与 consumer 的动态加入与离开 拉取系统 kafka broker 会持久化数据,consumer 采取 pull 的方式消费数据: 1.consumer 根据消费能力自主控制消息拉取速度 2.consumer 根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等 可扩展性 当需要增加 broker 结点时,新增的 broker 会向 zookeeper 注册,而 producer 及 consumer 会根据注册在 zookeeper 上的 watcher 感知这些变化,并及时作出调整。
|
|
|
|
|
|
|
|
|
9.消息类型 |
1. CONNECT:客户端连接到 MQTT 代理 2. CONNACK:连接确认 3. PUBLISH:新发布消息 4. PUBACK:新发布消息确认,是 QoS 1 给 PUBLISH 消息的回复 5. PUBREC:QoS 2 消息流的第一部分,表示消息发布已记录 6. PUBREL:QoS 2 消息流的第二部分,表示消息发布已释放 7. PUBCOMP:QoS 2 消息流的第三部分,表示消息发布完成 8. SUBSCRIBE:客户端订阅某个主题 9. SUBACK:对于 SUBSCRIBE 消息的确认 10. UNSUBSCRIBE:客户端终止订阅的消息 11. UNSUBACK:对于 UNSUBSCRIBE 消息的确认 12. PINGREQ:心跳 13. PINGRESP:确认心跳 14. DISCONNECT:客户端终止连接前优雅地通知 MQTT 代理
|
|
/ |
|
|
10.服务端实现 |
数十个 MQTT 服务器端程序 Mosquitto(C/C++) emqttd(Erlang/OTP) Moquette HiveMQ(Java) |
|
Scala 官方实现的系统 |
|
|
|
|
|
|
|
|
11.总结 |
两者都是从传统的 Pub/Sub 消息系统演化出来的,但是进化的方向不一样 。 Kafka 是为了数据集成的场景,通过分布式架构提供了海量消息处理、高容错的方式存储海量数据流、保证数据流的顺序等特性。 MQTT 是为了物联网场景而优化,提供多个 QoS 选项(exact once、at least once、at most once),还有层级主题、遗嘱等特性。
|
|
||
|
12.有意思的东西 |
Mqtt to Apache Kafka Connect https://github.com/evokly/kafka-connect-mqtt
Kafka MQTT Bridge Example https://github.com/mcollina/mosca/tree/master/examples/kafka Mosca supports different backends such as redis and mongodb, but also kafka. A Kafka MQTT Bridge application is included in the Mosca examples. |
|||
--------------------- 本文来自 wang 被注册了 的 CSDN 博客 ,全文地址请点击:https://blog.csdn.net/yeshenzzrff/article/details/79021479?utm_source=copy