

Hadoop
1、Hadoop 是什么
1.1、小故事版本的解释
小明接到一个任务:计算一个 100M 的文本文件中的单词的个数,这个文本文件有若干行,每行有若干个单词,每行的单词与单词之间都是以空格键分开的。对于处理这种 100M 量级数据的计算任务,小明感觉很轻松。他首先把这个 100M 的文件拷贝到自己的电脑上,然后写了个计算程序在他的计算机上执行后顺利输出了结果。
后来,小明接到了另外一个任务,计算一个 1T(1024G)的文本文件中的单词的个数。再后来,小明又接到一个任务,计算一个 1P(1024T) 的文本文件中的单词的个数……
面对这样大规模的数据,小明的那一台计算机已经存储不下了,也计算不了这样大的数据文件中到底有多少个单词了。机智的小明上网百度了一下,他在百度的输入框中写下了:大数据存储和计算怎么办?按下回车键之后,出现了有关 Hadoop 的网页。
看了很多网页之后,小明总结一句话:Hadoop 就是存储海量数据和分析海量数据的工具。
1.2、稍专业点的解释
Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是 HDFS 与 MapReduce。
HDFS 是一个分布式文件系统:引入存放文件元数据信息的服务器 Namenode 和实际存放数据的服务器 Datanode,对数据进行分布式储存和读取。
MapReduce 是一个计算框架:MapReduce 的核心思想是把计算任务分配给集群内的服务器里执行。通过对计算任务的拆分(Map 计算 /Reduce 计算)再根据任务调度器(JobTracker)对任务进行分布式计算。
1.3、记住下面的话:
Hadoop 的框架最核心的设计就是:HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,则 MapReduce 为海量的数据提供了计算。
把 HDFS 理解为一个分布式的,有冗余备份的,可以动态扩展的用来存储大规模数据的大硬盘。
把 MapReduce 理解成为一个计算引擎,按照 MapReduce 的规则编写 Map 计算 /Reduce 计算的程序,可以完成计算任务。
2、Hadoop 能干什么
大数据存储:分布式存储
日志处理:擅长日志分析
ETL: 数据抽取到 oracle、mysql、DB2、mongdb 及主流数据库
机器学习: 比如 Apache Mahout 项目
搜索引擎:Hadoop + lucene 实现
数据挖掘:目前比较流行的广告推荐,个性化广告推荐
Hadoop 是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。
实际应用:
(1)Flume+Logstash+Kafka+Spark Streaming 进行实时日志处理分析
<img src="https://pic2.zhimg.com/50/v2-fdaa7b4c0d7e2ae7d7c746d36d57c94c_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="1247"data-rawheight="475"data-default-watermark-src="https://pic4.zhimg.com/50/v2-2d98eaaaeaf8faf6ef12f6ab283dc76b_hd.jpg?source=1940ef5c"class="origin_image zh-lightbox-thumb"width="1247"data-original="https://pic1.zhimg.com/v2-fdaa7b4c0d7e2ae7d7c746d36d57c94c_r.jpg?source=1940ef5c"/>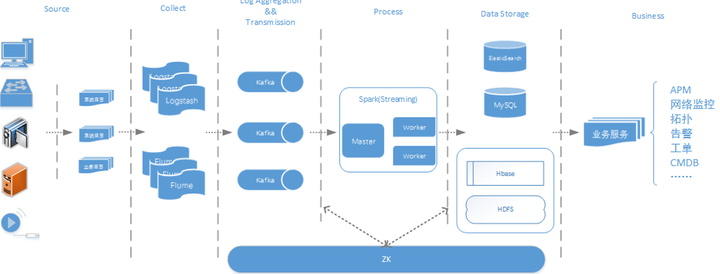
(2)酷狗音乐的大数据平台
<img src="https://pic1.zhimg.com/50/v2-0e338a5f6ee11fd90e739a379c12982f_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="823"data-rawheight="483"data-default-watermark-src="https://pic4.zhimg.com/50/v2-a64e34a3f43aa83c911e2a6d0d71b532_hd.jpg?source=1940ef5c"class="origin_image zh-lightbox-thumb"width="823"data-original="https://pic1.zhimg.com/v2-0e338a5f6ee11fd90e739a379c12982f_r.jpg?source=1940ef5c"/>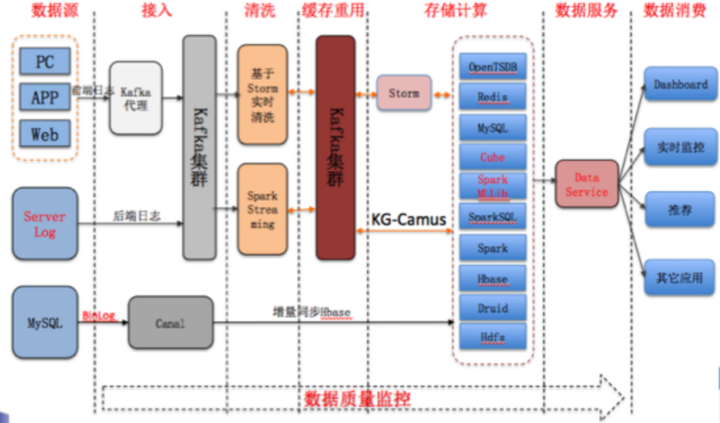
3、怎么使用 Hadoop
3.1、Hadoop 集群的搭建
无论是在 windows 上装几台虚拟机玩 Hadoop,还是真实的服务器来玩,说简单点就是把 Hadoop 的安装包放在每一台服务器上,改改配置,启动就完成了 Hadoop 集群的搭建。
3.2、上传文件到 Hadoop 集群
Hadoop 集群搭建好以后,可以通过 web 页面查看集群的情况,还可以通过 Hadoop 命令来上传文件到 hdfs 集群,通过 Hadoop 命令在 hdfs 集群上建立目录,通过 Hadoop 命令删除集群上的文件等等。
3.3、编写 map/reduce 程序
通过集成开发工具(例如 eclipse)导入 Hadoop 相关的 jar 包,编写 map/reduce 程序,将程序打成 jar 包扔在集群上执行,运行后出计算结果。
链接:https://www.zhihu.com/question/333417513/answer/795736712
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一、Hadoop
Hadoop 是一个开源的大数据框架,是一个分布式计算的解决方案。
Hadoop 的两个核心解决了数据存储问题(HDFS 分布式文件系统)和分布式计算问题(MapRe-duce)。
举例 1:用户想要获取某个路径的数据,数据存放在很多的机器上,作为用户不用考虑在哪台机器上,HD-FS 自动搞定。
举例 2:如果一个 100p 的文件,希望过滤出含有 Hadoop 字符串的行。这种场景下,HDFS 分布式存储,突破了服务器硬盘大小的限制,解决了单台机器无法存储大文件的问题,同时 MapReduce 分布式计算可以将大数据量的作业先分片计算,最后汇总输出。
二、Hadoop 特点
优点
1、支持超大文件。HDFS 存储的文件可以支持 TB 和 PB 级别的数据。
2、检测和快速应对硬件故障。数据备份机制,NameNode 通过心跳机制来检测 DataNode 是否还存在。
3、高扩展性。可建构在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,NameNode 也可以感知,将数据分发和备份到相应的节点上。
4、成熟的生态圈。借助开源的力量,围绕 Hadoop 衍生的一些小工具。
缺点
1、不能做到低延迟。高数据吞吐量做了优化,牺牲了获取数据的延迟。
2、不适合大量的小文件存储。
3、文件修改效率低。HDFS 适合一次写入,多次读取的场景。
三、HDFS 介绍
1、HDFS 框架分析
HDFS 是 Master 和 Slave 的主从结构。主要由 Name-Node、Secondary NameNode、DataNode 构成。
<img src="https://pic4.zhimg.com/50/v2-ddb9611f4f458e45c1e68f7de23444a1_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="463"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic3.zhimg.com/v2-ddb9611f4f458e45c1e68f7de23444a1_r.jpg?source=1940ef5c"/>
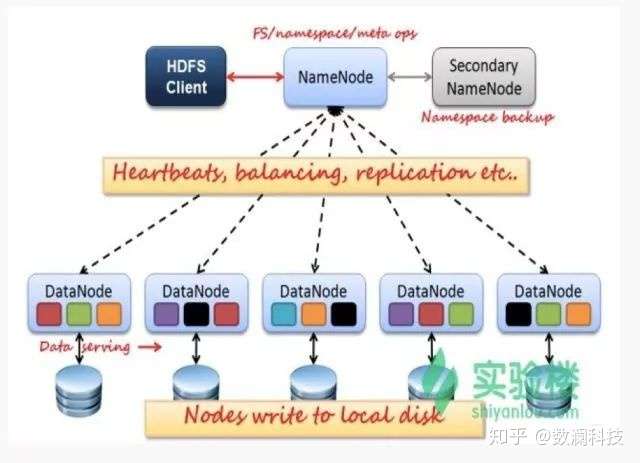
NameNode
管理 HDFS 的名称空间和数据块映射信存储元数据与文件到数据块映射的地方。
如果 NameNode 挂掉了,文件就会无法重组,怎么办?有哪些容错机制?
Hadoop 可以配置成 HA 即高可用集群,集群中有两个 NameNode 节点,一台 active 主节点,另一台 stan-dby 备用节点,两者数据时刻保持一致。当主节点不可用时,备用节点马上自动切换,用户感知不到,避免了 NameNode 的单点问题。
Secondary NameNode
辅助 NameNode,分担 NameNode 工作,紧急情况下可辅助恢复 NameNode。
DataNode
Slave 节点,实际存储数据、执行数据块的读写并汇报存储信息给 NameNode。
2、HDFS 文件读写
文件按照数据块的方式进行存储在 DataNode 上,数据块是抽象块,作为存储和传输单元,而并非整个文件。
<img src="https://pic1.zhimg.com/50/v2-83d48447b419a1c45534b22df0adbeed_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="305"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic3.zhimg.com/v2-83d48447b419a1c45534b22df0adbeed_r.jpg?source=1940ef5c"/>
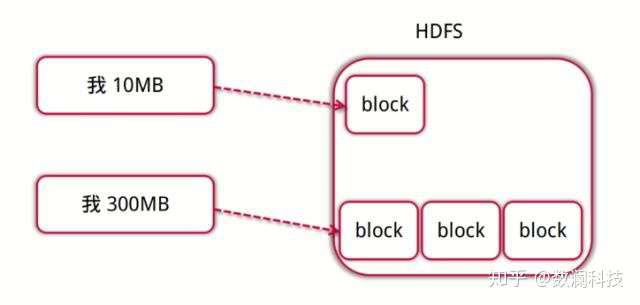
文件为什么要按照块来存储呢?
首先屏蔽了文件的概念,简化存储系统的设计,比如 100T 的文件大于磁盘的存储,需要把文件分成多个数据块进而存储到多个磁盘;为了保证数据的安全,需要备份的,而数据块非常适用于数据的备份,进而提升数据的容错能力和可用性。
数据块大小设置如何考虑?
文件数据块大小如果太小,一般的文件也就会被分成多个数据块,那么在访问的时候也就要访问多个数据块地址,这样效率不高,同时也会对 NameNode 的内存消耗比较严重;数据块设置得太大的话,对并行的支持就不太好了,同时系统如果重启需要加载数据,数据块越大,系统恢复就会越长。
3.2.1 HDFS 文件读流程
<img src="https://pic4.zhimg.com/50/v2-f7973b7974b464cc37d6cb2070450f0f_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="357"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic1.zhimg.com/v2-f7973b7974b464cc37d6cb2070450f0f_r.jpg?source=1940ef5c"/>
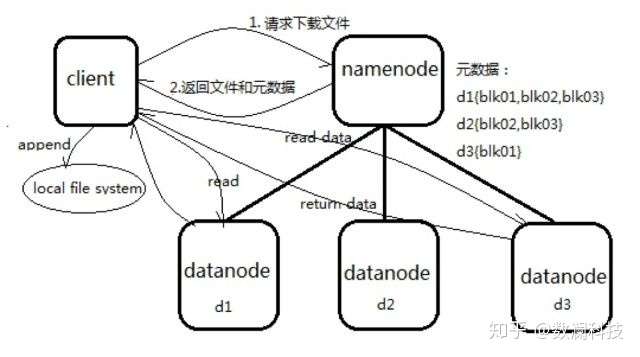
1、向 NameNode 通信查询元数据(block 所在的 DataNode 节点),找到文件块所在的 DataNode 服务器。
2、挑选一台 DataNode(就近原则,然后随机)服务器,请求建立 socket 流。
3、DataNode 开始发送数据(从磁盘里面读取数据放入流,以 packet 为单位来做校验)。
4、客户端已 packet 为单位接收,现在本地缓存,然后写入目标文件,后面的 block 块就相当于是 append 到前面的 block 块最后合成最终需要的文件。
3.2.2 HDFS 文件写流程
<img src="https://pic1.zhimg.com/50/v2-fb5c36df89639714da7313054e42f826_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="298"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic1.zhimg.com/v2-fb5c36df89639714da7313054e42f826_r.jpg?source=1940ef5c"/>
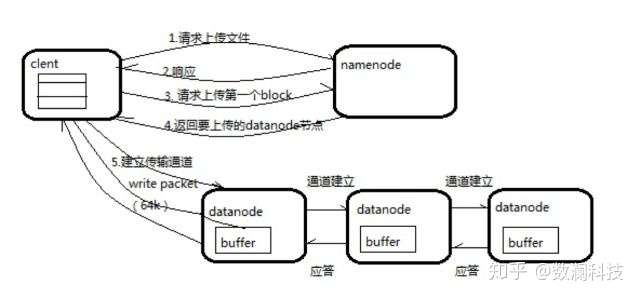
1、向 NameNode 通信请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
2、NameNode 返回确认可以上传。
3、client 会先对文件进行切分,比如一个 block 块 128m,文件有 300m 就会被切分成 3 个块,一个 128m、一个 128m、一个 44m。请求第一个 block 该传输到哪些 DataNode 服务器上。
4、NameNode 返回 DataNode 的服务器。
5、client 请求一台 DataNode 上传数据,第一个 DataNode 收到请求会继续调用第二个 DataNode,然后第二个调用第三个 DataNode,将整个通道建立完成,逐级返回客户端。
6、client 开始往 A 上传第一个 block,当然在写入的时候 DataNode 会进行数据校验,第一台 DataNode 收到后就会传给第二台,第二台传给第三台。
7、当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个 block 的服务器。
四、MapReduce 介绍
1、概念
MapReduce 是一种编程模型,是一种编程方法,是抽象的理论,采用了分而治之的思想。MapReduce 框架的核心步骤主要分两部分,分别是 Map 和 Reduce。每个文件分片由单独的机器去处理,这就是 Map 的方法,将各个机器计算的结果汇总并得到最终的结果,这就是 Reduce 的方法。
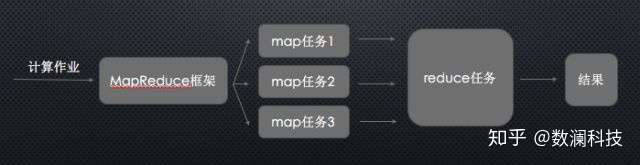
2、工作流程
向 MapReduce 框架提交一个计算作业时,它会首先把计算作业拆分成若干个 Map 任务,然后分配到不同的节点上去执行,每一个 Map 任务处理输入数据中的一部分,当 Map 任务完成后,它会生成一些中间文件,这些中间文件将会作为 Reduce 任务的输入数据。Reduce 任务的主要目标就是把前面若干个 Map 的输出汇总到一起并输出。
<img src="https://pic3.zhimg.com/50/v2-8ae80685f2e8095571c62bf184cdac0c_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="165"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic4.zhimg.com/v2-8ae80685f2e8095571c62bf184cdac0c_r.jpg?source=1940ef5c"/>
3、运行 MapReduce 示例
运行 Hadoop 自带的 MapReduce 经典示例 Word-count,统计文本中出现的单词及其次数。首先将任务提交到 Hadoop 框架上。
<img src="https://pic4.zhimg.com/50/v2-d64f8bca080fdb1b088c30cddce44995_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="89"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic2.zhimg.com/v2-d64f8bca080fdb1b088c30cddce44995_r.jpg?source=1940ef5c"/>

查看 MapReduce 运行结束后的输出文件目录及结果内容。
<img src="https://pic4.zhimg.com/50/v2-0dd0786a1cd80acc7da75521af7991a6_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="640"data-rawheight="108"class="origin_image zh-lightbox-thumb"width="640"data-original="https://pic2.zhimg.com/v2-0dd0786a1cd80acc7da75521af7991a6_r.jpg?source=1940ef5c"/>

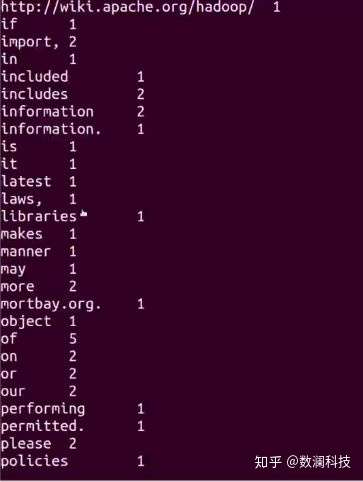
可以看到统计单词出现的次数结果
<img src="https://pic3.zhimg.com/50/v2-7cec8cf58a6547bedbaa506238e1cd27_hd.jpg?source=1940ef5c" data-caption="" data-size="normal"data-rawwidth="363"data-rawheight="482"class="content_image"width="363"/>
五、Hadoop 安装
墙裂推荐:史上最详细的 Hadoop 环境搭建https://blog.csdn.net/hliq5399/article/details/78193113/