Redis:一、基础必备知识
Redis 系列文章目录
@
一、什么是 NoSQL?
时代演进,网页开发可以概述为以下过程:
1、单机 Mysql 的引进:
初始时都是三层访问方式: (DAL 数据库访问层)
这种情况下,整个网站的瓶颈存在:
(1)、数据量太大,一个机器放不下;
(2)、访问量太多 ---- 读写混合,一个服务器受不了;
(3)、数据的索引 ----B+ Tree,一个机器放不了;
2、Memcached(缓存)+Mysql+ 垂直拆分:
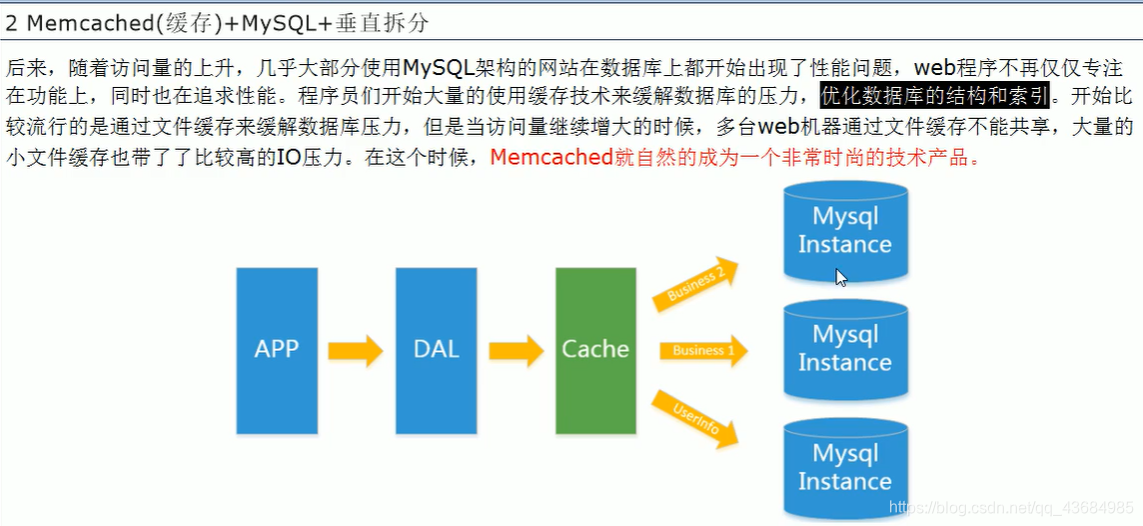
网站 80% 的时间都是在读数据,那么每次都去查询数据就很麻烦,因此使用缓存将每次读的数据存起来就可以减少服务器的压力!------------- 解决了大数据时代的读操作
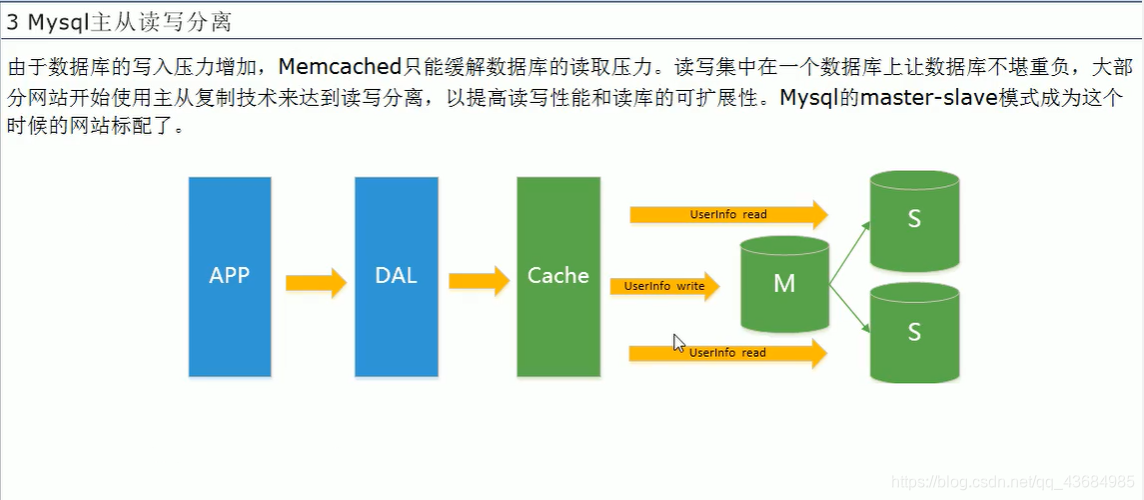
3、Mysql 主从复制、读写分离:
4、分库分表、水平拆分、mysql 集群:
在 Memcached 的高速缓存,MySQL 的主从复制、读写分离的基础上,由于 MySQL 主库的写压力开始出现了瓶颈,而数据量的猛增但是 MyISAM 使用表锁,在高并发下就会出现严重的锁问题,大量的高并发 MySQL 应用开始使用 InnoDB 引擎代替 MyISAM,它采用的是行锁,增加了并发性。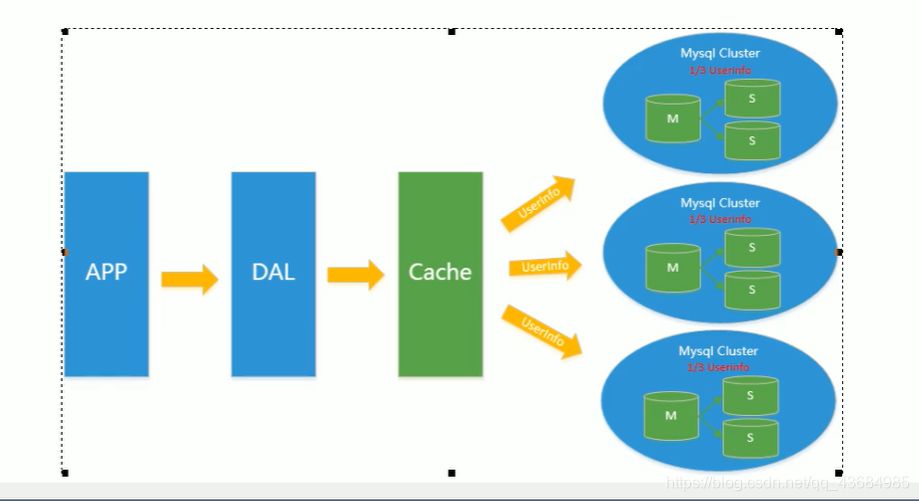
根据数据的使用频率或者其它条件来对数据进行数据库划分。比如电商中用户的不常修改的个人信息单独存放在一个数据库。每个数据库又划分为多张表,这样查询起来就更快了。
为什么使用 NoSQL?
NoSQL 是指非关系型数据库。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。NoSQL 数据库种类繁多,但是一个共同的特点就是去除掉了数据库的关系性。数据之间无关系,这样就非常容易扩展。也无形之间在架构的层面上带来了可扩展的能力。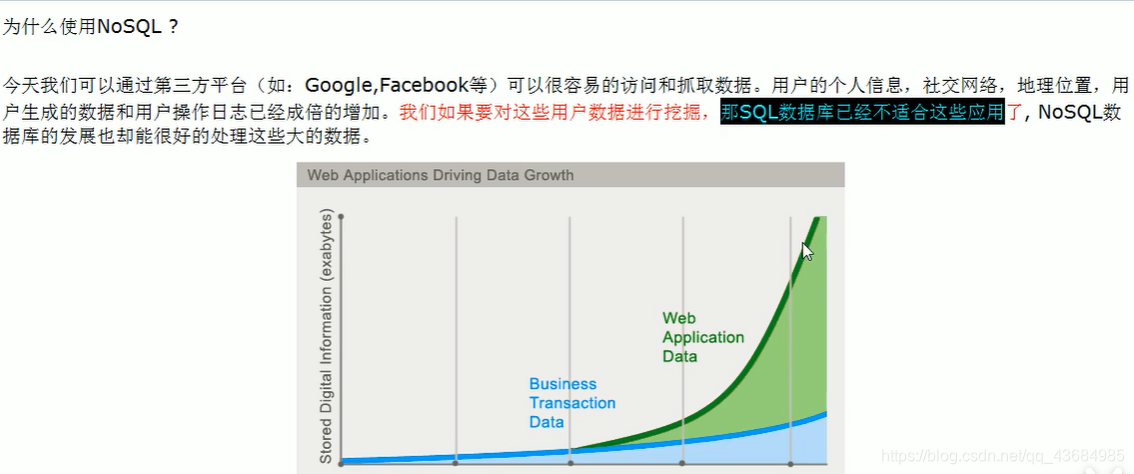
RDBMS 与 NoSQL 对比
RDBMS:
- 高度组织化结构数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中
- 数据操纵语言(DML),数据定义语言(DDL)
- 严格的一致性
- 基础事务
- 数据持久化存在在磁盘中
NoSQL:
- 不仅仅是 SQL
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,非 ACID 属性
- 包括 (Reids、MongDB 文档类、Memcache)
- 数据存储在内存中,但也支持存储在磁盘中了

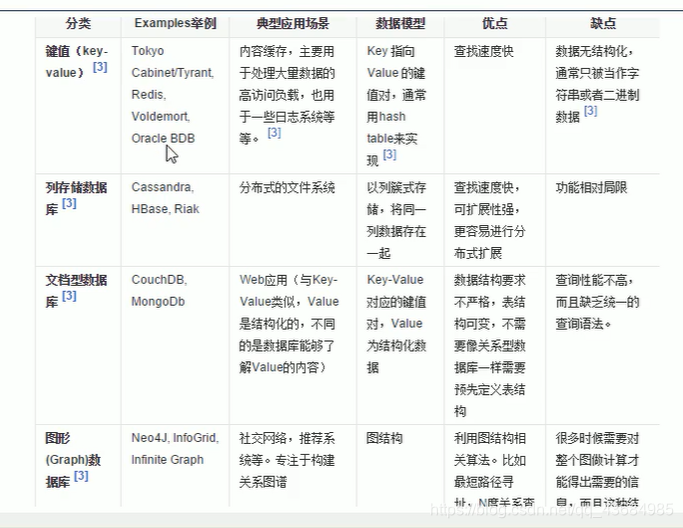
二、NoSQL 数据模型简介?
聚合模型:
- KV 键值 【memcache + redis】
- 文档型数据库 (bson 格式比较多) 【MongoDB】
- 列存储数据库 (分布式文件系统) 【Hbase】
- 图形关系数据库 (不是放图片的,放的是关系:比如朋友圈社交网络、广告推送系统)
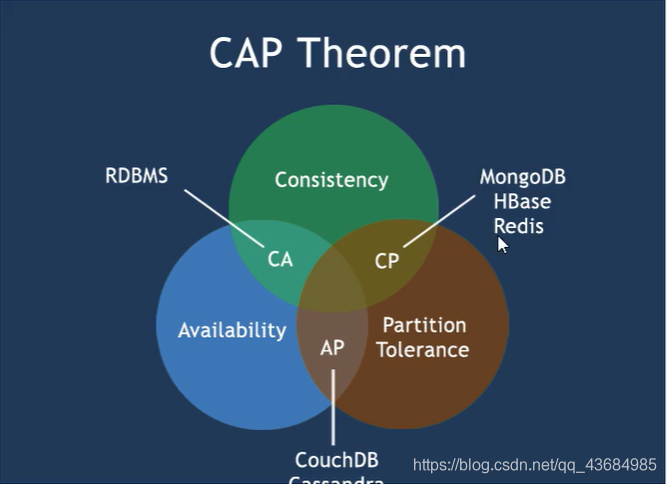
三、NoSQL 数据库 CAP 原理 CAP+BASE?
- 传统关系型数据库的 ACID 属性:

- NoSQL 的 CAP:
C:Consistency【强一致性】
A:Availablity【可用性】
P:Partition tolerance【分区容错性】
-
CAP 的三进二原则:


-
CAP 原则组合的应用场景:

-
BASE 原则理论:

-
分布式与集群的关联和区别:

四、 Redis 入门
下载安装好 redis 后将 redis 中的 redis.conf 配置文件拷贝一份到 /usr/local/redis/etc文件夹下, 在修改重要配置文件前先进行拷贝!!!!!
同时在这里我将一些重要的可执行指令也移动到了 /usr/local/redis/bin 目录下, 这些文件与 Redis 的启动 , 关闭 等息息相关.
4.1 修改 Redis 配置文件使得后台自启动
找到 redis.conf 配置文件中 daemonize no 这部分, 它的意思是 Redis 默认不会作为守护进程在后台自启动, 如果需要改为 true 即可.
4.2 Redis 启动, 关闭, 重启
redis-server 自定义配置文件xxx // 启动服务端
redis-cli -p 6379 // 启动客户端
ping // 测试连接
shutdown // 关闭
ps -ef | grep redis // 判断 redis 是否成功启动
lsof -i : 6379 // 判断 redis 是否成功启动
Redis 是单进程开始执行的, 它是通过 epoll 函数的包装来做到的.
Redis 默认有 16 个数据库, 可以通过 select 数据库编号 来调整使用数据库.
FLUSHDB // 清空当前库数据
FLUSHALL // 清空所有数据
4.3 Redis 常用数据类型及操作

(1) String 字符串数据类型
String 类型是二进制安全的,也就是说它可以保存任何数据,比如说图片、序列化后的对象。String 类型是基本数据类型,一个一个键最大能够存储 512MB。
String 类型的底层:
struct sdshdr {
long len;
long free;
char buf[];
};
其中 len:当前数据的存储长度;free:剩余的存储空间;buf:存储数据的数组。由于在 C# 中 byte 和 char 是等价的,因此可以看成是一个字节数组,当然就可以 包含任何数据了。

exists key的名字 // 判断某个 key 是否存在
move key db // 当前库就没有了,被移除了
expire key秒钟 // 给指定的 key 设置过期时间,已经过期的 key 就不会存在了,不是不能访问
ttl key // 看看还有多少秒过期 -1 表示永不过期、-2 表示已经过期
type key // 查看 key 是什么类型
set、get、del、append、strlen // 设置、获取、删除、追加、求长度
incr、decr、incrby、decrby // 数字加或者减
setrange、getrange // 范围设值、范围取值
setex(set with expire) 键 过期时间(秒) 值
setnx(set if not exist) // 不存在就设置值
mset、mget、msetnx // 多值设置、多值获取;注意多值操作有一个操作后续都会失效
(2) Hash 键值对组合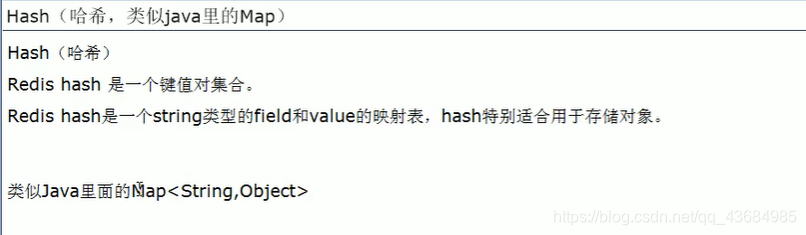
hset key1 name zhangsan // 一个 key 对应的是一个键值对
hget key1 name // 获取对应 key 的某个值
hmset key1 name zhangsan age 2 ..... // 一个 key 对应的是一个 Map 集合
hgetall key1 // 获取对应 key 的所有值
hdel key1 name // 删除 key1 对应的 name 这个键值对
hlen key1 // 获取 key1 对应的长度
hexists key1 // 在 Key 里面是否存在某个 key
hkeys/kvals // 获取所有的键值对中 所有键 / 所有值
hincrby/hincrbyfloat 键 值 // 给对应的键增加一定的值
hsetnx ........... // 不存在就设置值
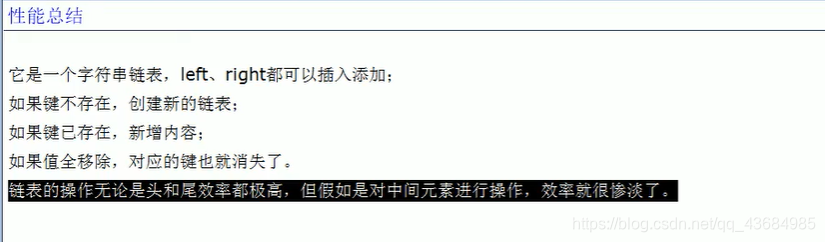
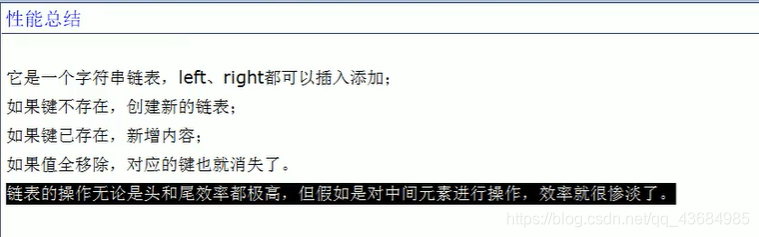
(3) List 列表
lpush 键 [列表值] // 从左边往右边插入
rpush 键 [列表值] // 从右边往左边插入
lpop 键 // 从最左边弹出一个
rpop 键 // 从最右边弹出一个
lindex 键 下标 // 从左边数获取指定下标的值
llen 键 // 获取列表的长度
lrem 键 n个value // 从左边起删除 n 个 value
ltrim 键 开始index 结束index // 截取指定键的某个范围的值然后赋给自身
lpoprpush 键1 键2 // 将 1 中左侧移到 2 的右侧
lset 键 下标 值 // 给指定位置赋值
linsert 键 before/after 值1 值2 // 在值 1 后面 (前面) 插入值 2
(4) Set 无序不可重列表
sadd 键 [值列表] // 添加值列表
smembers 键 // 获取键对应的值列表
scard 键 // 获取键中对应集合元素的个数
srem 键 值 // 删除某个值
srandmember key 某个整数 // 随机获取几个值
spop key // 随即出栈
smove key1 key2 key1中的某个值 // 将 key1 里的某个值赋值给 key2
sdiff set1 set2 // 输出仅仅在 set1 中出现的值
sinter set1 set2 // 输出同时在 set1 、 set2 中出现的值
sunion set1 set2 // 求 set1、set2 的并集
(5) Zset 有序集合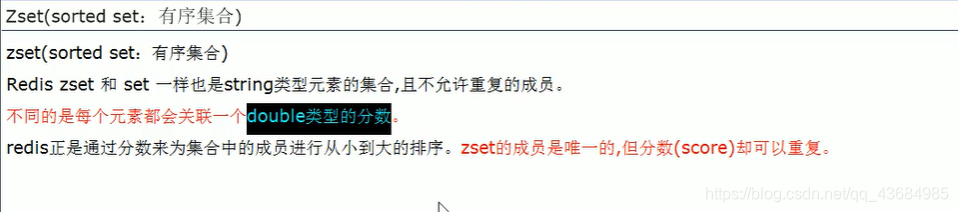
zadd key1 60 v1 70 v2 80 v3 90 v4 .... // 给 key1 设置键和值
zrange key1 0 -1 // 类似于 lrange 获取所有的键
zrange key1 0 -1 withscores // 获取所有的键 +score
zrevrange key1 0 -1 // 倒序获取所有值 (不包括 score)
zrevrange key1 0 -1 withscores // 倒序获取所有的键 +score
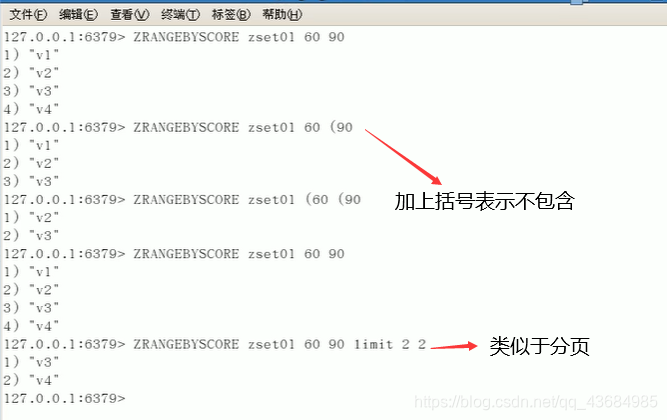
zrangebyscore key1 开始score 结束score limit xx xx // 按照 score 排序,limit 开始下标、多少步
zrem key1 某个value // 删除某个 socre 对应的 value
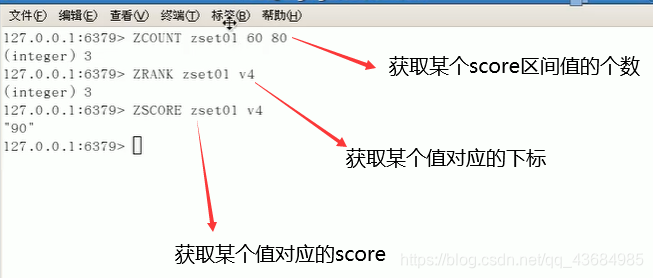
zcard key1 // 获取值的个数